Recent Dripline posts have covered what can be built on top of cryptographic hash functions: important concepts like data integrity and content provenance. Having the ability to uniquely refer to and verify an exact piece of data is crucial to building reliable digital content systems. But this can only take us so far. How can we keep track of an image when it’s been converted to a different file format? Or compressed? How can we match a song played in a noisy room to its original studio recording? Perceptual hashing answers these questions, and allows provenance information to travel far beyond the exact bits it was originally attached to.
Perceptual hash functions are designed differently than cryptographic hash functions, with algorithms that extract features from content and reduce them, outputting similar hashes for similar inputs. This means the compressed version of an image will have a hash that’s nearly the same as the original uncompressed image. These hashes can then be stored and compared to find matching images. This concept allows for powerful tools, from Shazam to Google’s reverse image search. At Hypha we want to take these tools further, to keep track of provenance even when media is altered.
Comparing basic, cryptographic, and perceptual hash functions
Let’s quickly revisit some of the basics. A hash function takes input data of any size (like someone’s name) and returns a fixed size output (like a number from 0-100). Reducing the size and type of the data can make referring to it easier. You can learn more about hash functions in this excellent interactive article by Sam Rose.
A cryptographic hash function adds certain constraints, for example that the function can’t be reversed easily and that collisions are difficult to find. This is what makes them so useful – all these properties mean the 32 bytes of output of a cryptographic hash function like SHA-256 can uniquely represent the input data, even if that data is terabytes in size.
One key property of cryptographic hash functions is that their output is randomly distributed, with no identifiable patterns or mapping. This results in the “avalanche effect.” Even a very small change in the input will cause a large change in the output. Similar inputs do not result in similar outputs. This is a desirable property for most scenarios, because it prevents attackers from being able to learn anything about the input data.
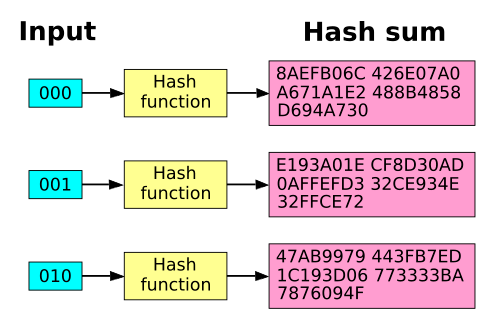
David Göthberg (public domain)
Perceptual hashing has the opposite goal: similar inputs should result in similar hash outputs. This property is the entire utility of perceptual hash functions. A good perceptual hash function will return similar outputs for an original image, as well as the compressed version of that image, for example – because both these input images look very similar.
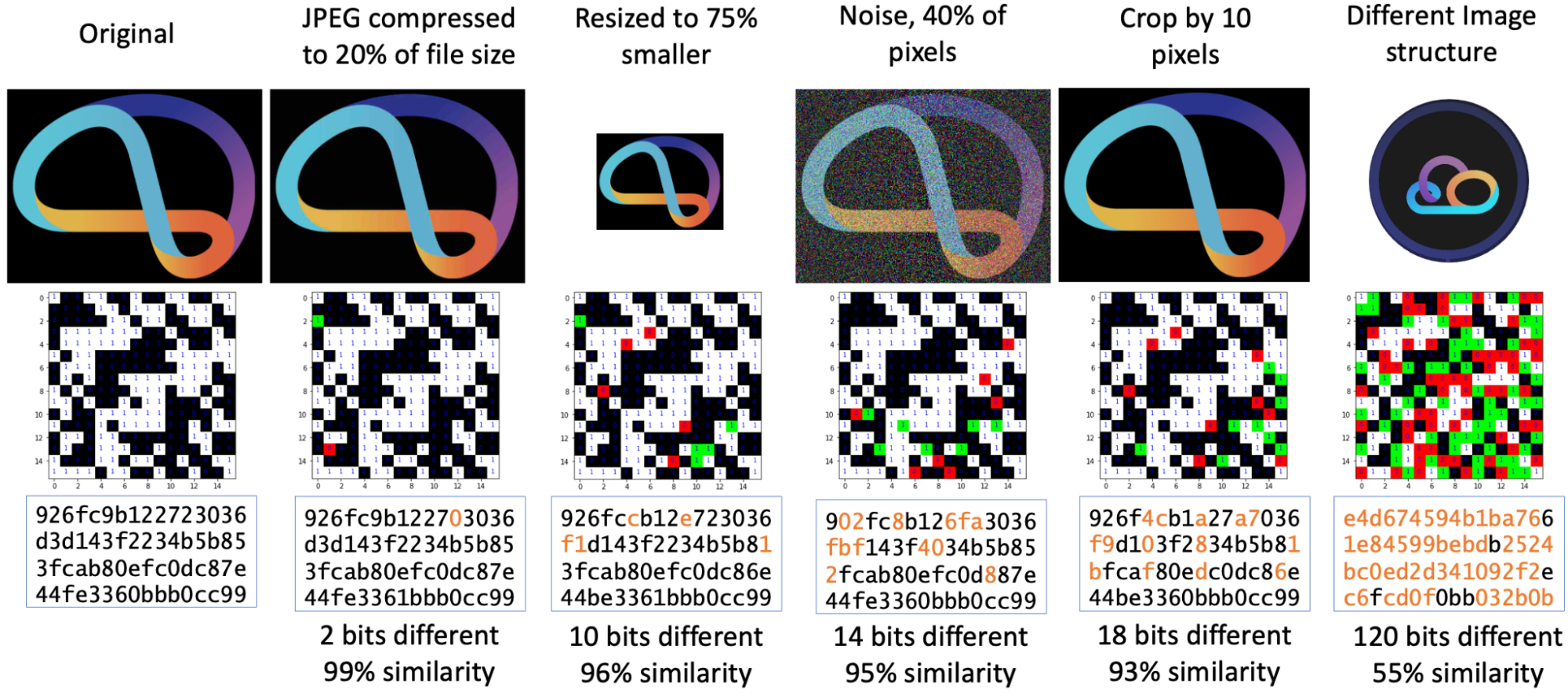
pdqhash (Apache 2.0)
While cryptographic hash functions operate on raw bytes, perceptual hash functions are specific to a type of media. There are different perceptual hash functions for images, video, audio, and other mediums. This is because a perceptual hash “is a fingerprint of a multimedia file derived from various features from its content” (phash.org), and the kinds of features available in an image vs video are different. If you’ve heard the term “audio fingerprint” before, that’s referring to an audio perceptual hash algorithm.
All these hash functions exist on a spectrum from shallow analysis to deep analysis. Cryptographic hash functions only compare exact bits, perceptual hash functions roughly compare media content (pixels, musical notes, etc.), and at the most intensive end of the scale, machine learning algorithms compare concepts like “a forest”. This article focuses on perceptual hashes because they nicely balance utility and efficiency: they can match content without being too computationally expensive to create or calculate.

How perceptual hash functions work
The final output of a perceptual hash function will be binary data of some length, such as 32 bytes or 256 KiB. The challenge of designing the algorithm is extracting the important parts from the media file and reducing those “features” down to just the small output size. For example Chromaprint–a perceptual hash algorithm aimed at music identification–extracts which 12 notes are being played in a provided song over time, filters that data to reduce it further, and then stores it as a set of integers that can be easily compared to find similar songs.
For image hashing, there are a variety of methods, but they all boil down to repeated reductions of the image data. First resize the image to some very small size, then convert to grayscale. Process the grayscale pixels in some relevant way, such as averaging the colours available, or applying the discrete cosine transform. Binarize the output from that process, and then take those bits as your hash output.

pdqhash (Apache 2.0)
As you can see, each perceptual hash function is quite different, especially across different input mediums. Understanding or creating the algorithm will often require some specialized knowledge in the domain (such as digital audio), as well as knowledge of signal processing and even machine learning.
Use cases for a perceptual hash function
Perceptual hashing is useful for any scenario that involves automatically finding similar media, especially at scale. An example is the Shazam app, which works by comparing a perceptual hash generated by your phone recording against their massive database of perceptual hashes for songs. Using a perceptual hash means songs can be found even in noisy environments–the underlying musical features can still be detected and matched.
This database lookup pattern is repeated in other domains, such as images. Social media companies often use perceptual hashing to check user-uploaded images against a database of banned content. That way reposts can be instantly detected and removed. Using a perceptual hash means that even if the user uploads a slightly altered image, it will still be flagged. Due to the massive volume of harmful content uploaded online, having an automated and accurate way to flag images or videos is very valuable. Facebook talks about this further in their 2019 article announcing their open source image perceptual hash, PDQ.
At Hypha, we’re interested in the content provenance use cases of perceptual hashing. For example, with our partner Starling Lab we store important image metadata in our database, all tied to the cryptographic hash of the original image. We’d like to use perceptual hashes so that metadata can still be matched to images that have been published or altered in different places, like on social media or news websites. It’s also helpful when our original image can’t be shared publicly, as it might include private metadata like a geotag.
Even at a small scale, integrating perceptual hashes into content provenance workflows is useful. We believe it’s more important than ever to publish and retrieve these hashes, as part of a digital trust system. These kinds of systems can help combat the rise of AI-generated media and the decline of faith in traditional institutions.
Any usage of perceptual hashes must take into account their fallibility. Unlike cryptographic hashes, they cannot be relied on as a guarantee. Sometimes dissimilar images will have similar hashes; sometimes similar images will have dissimilar hashes. A good algorithm will reduce these scenarios, but can never eliminate them. A well-designed system (such as one for moderation) will use perceptual hashes as a guide rather than an absolute indicator.
Hypha has been experimenting with open source perceptual hash algorithms, so stay tuned for our next blog post on this topic!